Using vaderSentiment to Intuitively Predict the Sentiment of Social Media Posts
Taylor Ray and Sujan Anreddy
January 14, 2021
-
Facebook
-
Twitter
Social Media in a Pandemic: Helpful or Harmful?
During any global event, the medium through which individuals are getting updated news and information about that event is incredibly important—especially in a situation like the current COVID-19 pandemic, where failure to obtain information that is accurate and reliable can have serious effects on one’s overall health and potentially even their life.
In our digitally-driven world, social media plays a tremendous role as a media outlet for younger and older groups alike. Ideally, social media is a powerful tool when a person can easily distinguish factual information from (mis)information, but this can be difficult to do when social media platforms and the authors of posts are not making this obvious and/or the social media user is very impressionable.
Fortunately, with access to data being shared and consumed via social media, the opportunity exists to perform analysis of the emotions being experienced through metadata like comments on a YouTube video, the likes a Facebook post received, the dislikes on the post, trending hashtags, and so on. Better yet, for those that are tech-savvy, the chance exists to do sentiment analysis of social media text programmatically. Before diving into the methodology for performing this kind of analysis, there are a few questions we should ask before using social media data as an input source.
What Makes Social Media Data Different from Other Data?
The language used across social media is quite different from that used for writing a research paper or composing an email to a boss or colleague. With that realization in mind, I’d like to take note of a few attributes that make up social media vernacular, all of which I’ll demonstrate through YouTube video comments related to the pandemic:
Emoticons. Shortened for “emotion icon,” emoticons are helpful in that they allow for clear, picture-like representations of emotions and facial expressions that would otherwise be interpreted by the use of language and punctuation alone.
“Nice video 👍”
“Great job… 🙌”
“Please don’t take this virus lightly 🙏 Stay home and be safe 🙏”
“💯💯”
Shortened text. Shortened text could mean one of two things, though it tends to mean exactly what it says: text that is shorter and less elaborate overall. Depending on the context, shortened text can mean that few words are used throughout the entirety of a phrase or sentence, while other instances might contain individual words that are themselves shortened.
“Thx for this, I learned a lot.”
“Shame!”
“wow”
“Ur welcome!”
Acronyms and slang. Social media is a highly coded language, where acronyms (e.g., “LOL,” “WTF,” “IDK,” and “SMH”) and slang (e.g., “nah,” “sux,” and “coz”) are major components.
“With all of us wearing our pretty dresses and skirts should bring back the curtsy. LOL! Parents who are concerned with curriculum could also go to Easy Peasy Homeschool. It’s free. What I’m doing during social distancing? Lots of food prepping, catching up on spring cleaning and hanging out with family. Maybe we’ll get out on a hike soon.”
“Gene, FYI NO NSAIDs if infected with the Corona virus!”
“There is even a homeschooling group called homeschoolgameschool. They are on FB”
“I don’t think so that we need to know it coz we already know it”
How Can We Programmatically Analyze Its Sentiment?
While there are many programming tools for predicting sentiment, very few of them take the nature and elements of social media text into account, deeming them to be fairly inaccurate. Fortunately, C.J. Hutto and Eric Gilbert, two individuals with the common goal of contributing to human-computer interactions, had the stroke of genius to develop a sentiment-based tool called vaderSentiment [1].
Standing for Valence Aware Dictionary for sEntiment Reasoning, VADER is a rule-based model designed to take in text that has been pulled from social media and spit out the overall sentiment polarity (“positive,” “neutral,” or “negative”) that the phrase or sentence has.
It’s able to do this effectively because it has a few features that are unlike other existing tools in the natural language processing domain:
- it accounts for sentiment-bearing features that are native to social media content (e.g., emoticons, abbreviations, acronyms, slang, etc.)
- it is built on a lexicon that isn’t very noisy, meaning it has a reduced number of elements that have neutral polarity and would otherwise undermine the end classification
- it is a “gold-standard” lexicon consisting of over 7,500 words, meaning the lexicon has been validated by humans
- it is rule-based and accounts for other commonalities among text such as punctuation, capitalization, degree modifiers, conjunctions, and negations
Now that we’ve introduced the tool and the advantages it provides, let’s briefly discuss using it with the Python programming language.
1. First, before we can use this library for sentiment analysis, we need to install it via the command line.
pip install vaderSentiment2. After successfully installing the library using pip, add a line at the top of your program to import the installed library for use throughout your program.
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer3. Next, to use this library for extracting the sentiment intensity of text from social media, we need to feed it some text to see results.
Before we can do that, we need to initialize a sentiment analyzer object.
In other words, we need to define some meaningful variable (e.g., something appropriately named as “sentiment_analyzer,” “analyzer,” or whatever suits your fancy), and set it equal to what the vaderSentiment library calls their SentimentIntensityAnalyzer object.
Doing this will ensure that we can easily perform certain VADER operations by linking each operation to the analyzer.
analyzer = SentimentIntensityAnalyzer()4. After we’ve initialized the sentiment analyzer, we’re at the stage of giving the tool some data.
In this example, API calls are being made across the YouTube Data API v3, and the data returned from those calls is exported into JavaScript Object Notation (JSON) format by default.
More often than not, JSON files will contain pieces of information that we don’t care to test vaderSentiment on. Thankfully, JSON gives us the ability to extract desired pieces of information by indexing.
For example, say I have a JSON file containing YouTube data, but I’m only interested in pulling the exact text corresponding to comments left on YouTube videos and not interested in the other objects within the JSON file. I could access that data with the following:


5. Now that we know how to access specific pieces of data from a JSON file, we can look at the sentiment within that data.
I have stored all of the plain text comments in a single array, which I have named appropriately as—you guessed it—comments.
Since vaderSentiment is currently only compatible with English text, the elements of the comments array can be passed through Python’s library version of Google Translate, googletrans. Much like vaderSentiment, both a pip install and object initialization are required to use googletrans.

Then we can use a simple for loop to iterate over each comment contained within that larger array of translated comments and analyze the sentiment accordingly.
Before showing what that for loop would look like, it’s also important to emphasize how to numerically separate and distinguish the sentiment level categories from one another (i.e., define the criteria that makes one comment neutral and another positive or negative).
Each phrase or sentence used with VADER has an attribute called a compound score, which is computed by (1) summing each word’s valence score, (2) applying general rules for things like punctuation, capitalization, and degree modifiers, and (3) normalizing the value to lie somewhere between -1 and +1.
With those processes noted, the general rule of thumb for the sentiment levels looks is as follows:
- positive samples possess compound scores >= 0.05
- neutral samples possess compound scores > -0.05 and < 0.05
- negative samples possess compound scores <= -0.05
The for loop in Python reflects those same classifications:

6. Lastly, we want an effective way to present the data and validate our results.
A multitude of options for storing data exist, but I’ve opted to store the YouTube data in a Pandas DataFrame. Pandas is a data analysis and manipulation library intended for use with Python, and within that library, there is functionality for creating a two-dimensional table that can be easily catered to various styles of data. The table can also be exported as a comma-separated values (CSV) file.
Helpful documentation for the Pandas DataFrame is noted in this blog’s references [2].
When creating the DataFrame, we’re able to attach the array containing the sentiment levels for each YouTube comment as one of the table’s columns:
- Before reporting the accuracies observed in my implementations with VADER, I’d like to report the accuracies that came from the authors’ original experiments [1].
Hutto and Gilbert relied on three metrics to quantify their tool’s ability to classify sentiment:
- precision: # of true classifications / # of elements labeled as that class
- recall: # of true classifications / # of elements known to belong to that class
- F1 score: overall accuracy, or the harmonic mean of precision and recall
Their tests using VADER across 4,200 Twitter tweets, 3,708 Amazon product reviews, 10,605 movie reviews, and 5,190 NY Times editorials yielded F1 scores of 0.96, 0.85, 0.61, and 0.55, respectively. These values indicated that, on average, VADER was the most accurate and highest performing lexicon when put to the test with social media text from Twitter, and just as good (if not better) than its counterparts across the remaining domains. Now, we can carry on with some tests of our own.
Typically, when evaluating classifiers of any sort, is it recommended that you use an already labeled dataset as the basis for testing. The unfortunate reality is that there are few, if any, readily available datasets containing sentiment-labeled YouTube data. There are, however, datasets for other social media platforms on the web that have accounted for sentiment. I was able to find a dataset that captured tweets in February of 2015 about people’s personal experiences with major U.S. airlines (e.g., Southwest, United, and Delta). Each contributor was asked to classify their tweet under the umbrella of being positive, neutral, or negative. This dataset was made available by Kaggle [3], a site that has a reputation for providing open-source code and datasets for machine learning and data science applications.
Preprocessing of the Data
Again, the Twitter Airlines dataset mentioned above was chosen to serve as the ground truth or “gold-standard” classifications. However, given the flawed nature of most data, it is naive to assume that there are no underlying issues with the dataset that need addressing. An “issue” with this dataset is an uneven distribution of sentiment labels across the entire dataset. In other words, the number of tweets labeled as positive, neutral, and negative is not the same:
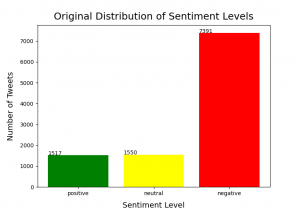
As we can see, a significant portion of the entries fall under the negative class. This isn’t all that shocking though, as people tend to leave reviews as a result of negative experiences more than average or positive ones. While this characteristic of being imbalanced does not affect the testing being done for this classifier, it could create an implicit bias for some classifiers in the machine learning realm (i.e., the classifier would fail to categorize the input text under its rightful label because it has been overtrained on one label more than the rest). This scenario, often referred to as the “imbalance problem” or the “class imbalance problem”, can be tackled in a few different ways [4, 5]. The approach used for balancing here is undersampling [6], which is the process of removing samples from the majority classes until they match up to meet the minority class. Regardless of the type of classifier being used, I think this is something good to do in practice. See the balanced dataset below:
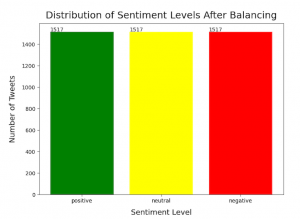
Apart from balancing the data, other steps performed to strengthen VADER’s ability to predict sentiment included:
- Filtering the dataset to only include tweets having a sentiment label confidence of 0.90 or greater (i.e., the tweets that were more confidently thought to fall under one sentiment level or the other)
- Removing the portion of each tweet that is used to mention another Twitter account or user (e.g., “@united” or “@AmericanAir”)
- Translating numeric and named HTML entities to be represented as unicode strings (“&” to “&” and “<” to “<”)
Evaluating VADER Sentiment
I wanted to utilize precision, recall and the F1 score for evaluation as the creators of VADER did. Plus, I find that these are the most common metrics used among the data science community. While we could manually calculate these values, scikit-learn provides a multi-part function that generates what they refer to as a classification report [7]. Conveniently, this classification report captures those three values that we are after.
Subsequently, the following values were produced:
Another metric that can be useful for gauging the classifier’s performance is the confusion matrix: a table that can be computed for tasks where the true labels are known. It helps in determining the number of items that were incorrectly labeled as any of the other classes, as well as the number of items that were correctly labeled as the correct class. Following sentiment analysis on this data, the confusion matrix to the right was produced as a heatmap:
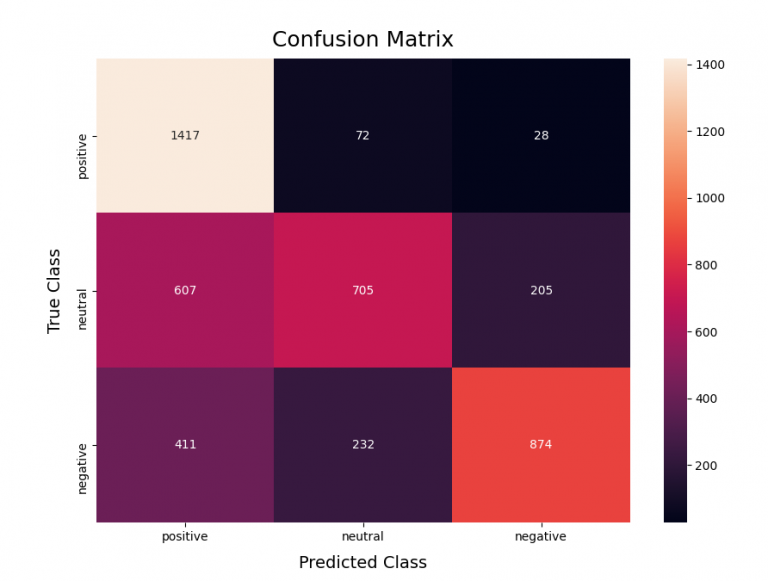
Now let’s see if VADER performed as expected by considering some of the claims made by Hutto and Gilbert in the tool’s paper [1]:
“…when compared to sophisticated machine learning techniques, the simplicity of VADER carries several advantages. First, it is both quick and computationally economical without sacrificing accuracy.”
While this blog does not provide sufficient information for comparing VADER to machine learning techniques, it does help in confirming the quality of being “computationally economical” like the authors suggest. In timing the experiment included here, which was run on a laptop having a modest 2.7GHz processor and 16GB RAM, all 4,551 tweets were analyzed in under a second (~0.56 seconds).
“By exposing both the lexicon and rule-based model, VADER makes the inner workings of the sentiment analysis engine more accessible (and thus, more interpretable) to a broader human audience beyond the computer science community. Sociologists, psychologists, marketing researchers, or linguists who are comfortable using LIWC should also be able to use VADER.”
I find this statement to hold true. When introducing VADER to researchers from the social science community—most of whom have little to no prior programming experience—I found that they were able to follow along with steps required to use VADER. In addition to its interpretability, the underlying lexicon and grammatical rules on which the tool is based were second nature to many social scientists who already had a deep understanding of linguistics. I think the tool can be utilized by anyone interested in exploring sentiment.
Ultimately, VADER seems to be a good option for sentiment tasks that value ease of use and quick processing time over perfect accuracy. Some ideas for improvement include:
- Using a dataset that has been collaboratively labeled by groups of individuals rather than a single individual
- Tweaking the threshold that determines the sentiment levels (e.g., changing 0.05 to 0.005 or 0.5)
- Using a hybrid method of classification (e.g., pairing vaderSentiment with other machine learning techniques)
I hope that this tutorial-like introduction to vaderSentiment was able to showcase the tool’s ability to predict the sentiment of social media text. I believe it can be used to identify the emotional spectrum that accompanies very real-world discussions occurring through social media posts.
If you’re looking for additional details regarding vaderSentiment and the code that is used to make it happen, visit the tool’s GitHub page [8].
References
[1] C. J. Hutto and E. Gilbert, “VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text,” Association for the Advancement of Artificial Intelligence. [Online]. Available: https://www.aaai.org/ocs/index.php/ICWSM/ICWSM14/paper/viewPaper/8109. [Accessed: 05-Jan-2021].
[2] “pandas.DataFrame,” pandas.DataFrame – pandas 1.1.2 documentation. [Online]. Available: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html. [Accessed: 25-Sep-2020].
[3] “Your Machine Learning and Data Science Community,” Kaggle. [Online]. Available: https://www.kaggle.com/. [Accessed: 09-Oct-2020].
[4] M. Buda, A. Maki, and M. A. Mazurowski, “A systematic study of the class imbalance problem in convolutional neural networks,” arXiv.org, 13-Oct-2018. [Online]. Available: https://arxiv.org/abs/1710.05381. [Accessed: 04-Jan-2021].
[5] S. Kotsiantis, D. Kanellopoulos, and P. Pintelas, “Handling imbalanced datasets: A review,” Semantic Scholar, 01-Jan-1970. [Online]. Available: https://www.semanticscholar.org/paper/Handling-imbalanced-datasets:-A-review-Kotsiantis-Kanellopoulos/95dfdc02010b9c390878729f459893c2a5c0898f. [Accessed: 04-Jan-2021].
[6] K. Pykes, “Oversampling and Undersampling,” Medium, 10-Sep-2020. [Online]. Available: https://towardsdatascience.com/oversampling-and-undersampling-5e2bbaf56dcf. [Accessed: 04-Jan-2021].
[7] “sklearn.metrics.classification_report,” scikit-learn. [Online]. Available: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.classification_report.html. [Accessed: 04-Jan-2021].
[8] cjhutto, “cjhutto/vaderSentiment,” GitHub. [Online]. Available: https://github.com/cjhutto/vaderSentiment. [Accessed: 25-Sep-2020].